


K8S master 节点更换 IP 与高可用故障模拟实战
一、前言
根据小伙伴提的问题,这里专门出一篇文章分析 master 节点挂了不可用的场景分析,希望这篇文章对小伙伴有用;其实 VIP 的方案实现高可用,还有更可靠的方案,也是我们目前生成环境在使用的高可用方案,后面也会分享出来,请小伙伴耐心等待~
二、配置 多个 master 节点
如果直接部署单 master 或者多 master k8s 环境,可以参考这篇文章:Kubernetes(k8s)最新版最完整版环境部署+master 高可用实现
1)节点信息
| hostname | IP | 节点类型 |
|---|---|---|
| local-168-182-110,cluster-endpoint | 192.168.182.110,VIP:192.168.182.220 | master |
| local-168-182-111 | 192.168.182.111 | node |
| local-168-182-112 | 192.168.182.112 | node |
| local-168-182-113 | 192.168.182.112 | master backup1 |
| local-168-182-130 | 192.168.182.112 | master backup2 |
1)安装 docker 或 containerd
# 配置yum源
cd /etc/yum.repos.d ; mkdir bak; mv CentOS-Linux-* bak/
# centos7
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# centos8
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo
# 安装yum-config-manager配置工具
yum -y install yum-utils
# 设置yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce版本
yum install -y docker-ce
# 启动
systemctl start docker
# 开机自启
systemctl enable docker
# 查看版本号
docker --version
# 查看版本具体信息
docker version
# Docker镜像源设置
# 修改文件 /etc/docker/daemon.json,没有这个文件就创建
# 添加以下内容后,重启docker服务:
cat >/etc/docker/daemon.json<<EOF
{
"registry-mirrors": ["http://hub-mirror.c.163.com"]
}
EOF
# 加载
systemctl reload docker
# 查看
systemctl status docker containerd2)安装 kubeadm,kubelet 和 kubectl
1、配置 k8s yum 源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[k8s]
name=k8s
enabled=1
gpgcheck=0
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
EOF2、修改 sandbox_image 镜像源
# 导出默认配置,config.toml这个文件默认是不存在的
containerd config default > /etc/containerd/config.toml
grep sandbox_image /etc/containerd/config.toml
sed -i "s#k8s.gcr.io/pause#registry.aliyuncs.com/google_containers/pause#g" /etc/containerd/config.toml
# 或者
sed -i "s#registry.k8s.io/pause#registry.aliyuncs.com/google_containers/pause#g" /etc/containerd/config.toml
# 检查
grep sandbox_image /etc/containerd/config.toml3、配置 containerd cgroup 驱动程序 systemd
kubernets 自v 1.24.0 后,就不再使用 docker.shim,替换采用 containerd 作为容器运行时端点。因此需要安装 containerd(在 docker 的基础下安装),上面安装 docker 的时候就自动安装了 containerd 了。这里的 docker 只是作为客户端而已。容器引擎还是
containerd。
sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml
# 应用所有更改后,重新启动containerd
systemctl restart containerd4、开始安装 kubeadm,kubelet 和 kubectl
# 不指定版本就是最新版本,当前最新版就是1.25.4
yum install -y kubelet-1.25.4 kubeadm-1.25.4 kubectl-1.25.4 --disableexcludes=kubernetes
# disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库
# 设置为开机自启并现在立刻启动服务 --now:立刻启动服务
systemctl enable --now kubelet
# 查看状态,这里需要等待一段时间再查看服务状态,启动会有点慢
systemctl status kubelet
# 查看版本
kubectl version
yum info kubeadm5、master 节点加入 k8s 集群
# 证如果过期了,可以使用下面命令生成新证书上传,这里会打印出certificate key,后面会用到
CERT_KEY=`kubeadm init phase upload-certs --upload-certs|tail -1`
# 其中 --ttl=0 表示生成的 token 永不失效. 如果不带 --ttl 参数, 那么默认有效时间为24小时. 在24小时内, 可以无数量限制添加 worker.
echo `kubeadm token create --print-join-command --ttl=0` " --control-plane --certificate-key $CERT_KEY --v=5"
# 拿到上面打印的命令在需要添加的节点上执行
# --control-plane 标志通知 kubeadm join 创建一个新的控制平面。加入master必须加这个标记
# --certificate-key ... 将导致从集群中的 kubeadm-certs Secret 下载控制平面证书并使用给定的密钥进行解密。这里的值就是上面这个命令(kubeadm init phase upload-certs --upload-certs)打印出的key。
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config查看节点
kubectl get nodes
kubectl get nodes -owide
三、更换 K8S master 节点 IP(master 高可用)
1)节点信息
| hostname | IP | 节点类型 |
|---|---|---|
| local-168-182-110,cluster-endpoint | 192.168.182.110,VIP:192.168.182.220 | master |
| local-168-182-111 | 192.168.182.111 | node |
| local-168-182-112 | 192.168.182.112 | node |
| local-168-182-113 | 192.168.182.112 | master backup1 |
| local-168-182-130 | 192.168.182.112 | master backup2 |
2)master 节点安装 keepalived
1、安装 keepalived
yum install keepalived -y2、配置 keepalived
master
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from fage@qq.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.182.220/24
}
track_script {
check_nginx
}
}
EOFmaster backup1
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from fage@qq.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 90 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.182.220/24
}
track_script {
check_nginx
}
}
EOFmaster backup2
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from fage@qq.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 80 # 优先级,备服务器设置 80
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.182.220/24
}
track_script {
check_nginx
}
}
EOF3、启动并设置开机启动
systemctl daemon-reload
systemctl restart keepalived && systemctl enable keepalived && systemctl status keepalived
# 查看
ip a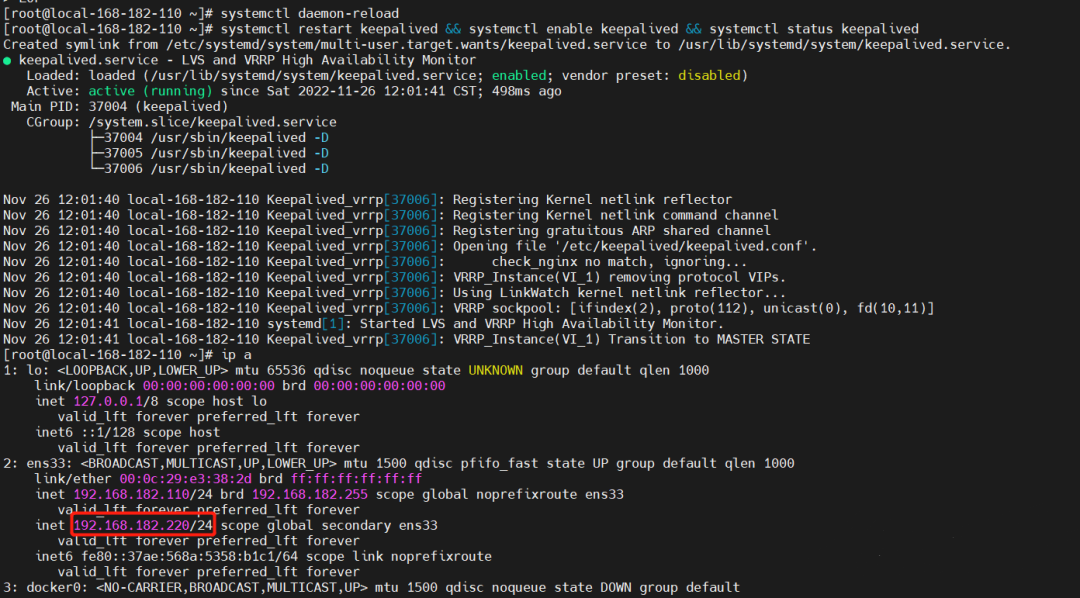
3)配置 hosts
这里设置 cluster-endpoint 为 VIP hostname:
192.168.182.110 local-168-182-110
192.168.182.111 local-168-182-111
192.168.182.112 local-168-182-112
192.168.182.113 local-168-182-113
# VIP
192.168.182.220 cluster-endpoint4)修改配置
到 K8S master 节点/etc/kubernetes/manifests目录下,我们主要修改etcd.yaml,kube-apiserver.yaml这两个配置文件。
# 这里使用sed批量替换
cd /etc/kubernetes/
# 先查
grep -rn '192.168.182' *
# 替换ip
sed -i 's/192.168.182.110/192.168.182.220/g' `grep -rl ./`
# 替换域名
sed -i 's/local-168-182-110/cluster-endpoint/g' `grep -rl ./`
# 检查
grep -r '192.168.182' *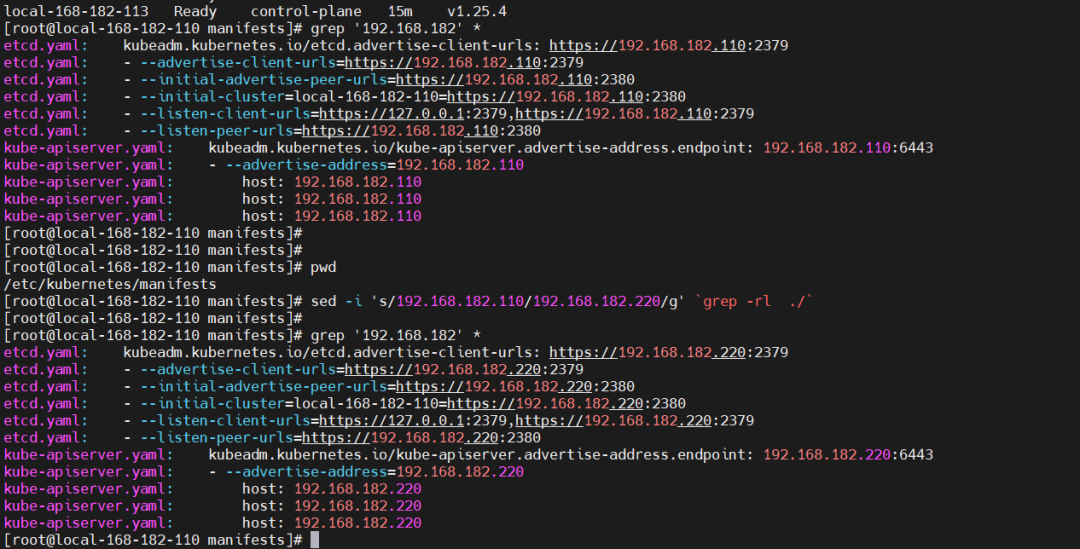
5)生成新的 admin 用 config 文件
cd /etc/kubernetes
mv admin.conf admin.conf_bak
# 使用如下命令生成新的admin.conf
kubeadm init phase kubeconfig admin --apiserver-advertise-address 192.168.182.220
# cluster-endpoint-》192.168.182.220
sed -i 's/192.168.182.220/cluster-endpoint/g' admin.conf6)删除旧的证书,生成新证书
cd /etc/kubernetes/pki
# 先备份
mv apiserver.key apiserver.key.bak
mv apiserver.crt apiserver.crt.bak
# 使用如下命令生成
kubeadm init phase certs apiserver --apiserver-advertise-address 192.168.182.220 --apiserver-cert-extra-sans "192.168.182.220,cluster-endpoint"
# --apiserver-cert-extra-sans "192.168.182.220,cluster-endpoint":设置了这个,之后加入节点验证证书阶段就不会报错了。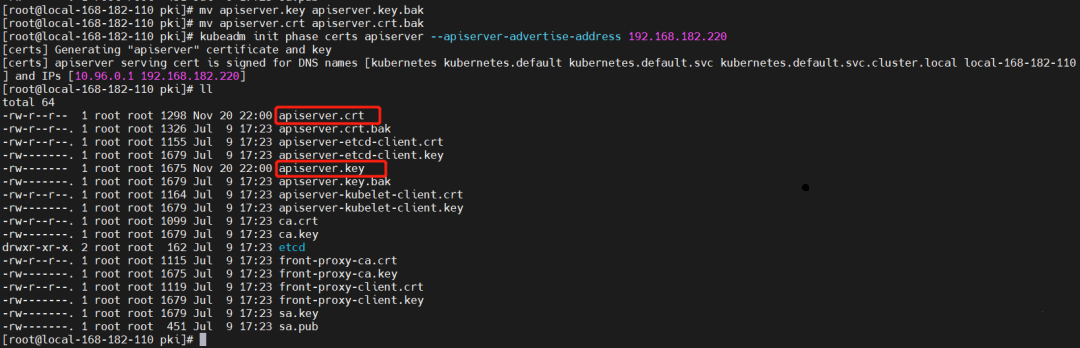
7)重启 docker 或者 containerd,kubelet
systemctl restart docker containerd kubelet
# 查看,可以看到master节点现在已经起来了
cd /etc/kubernetes
kubectl get nodes --kubeconfig=admin.conf
# 修改配置,后续可以使用kubectl get nodes查看K8S集群状态了
cd /etc/kubernetes
cp admin.conf ~/.kube/config
kubectl get nodes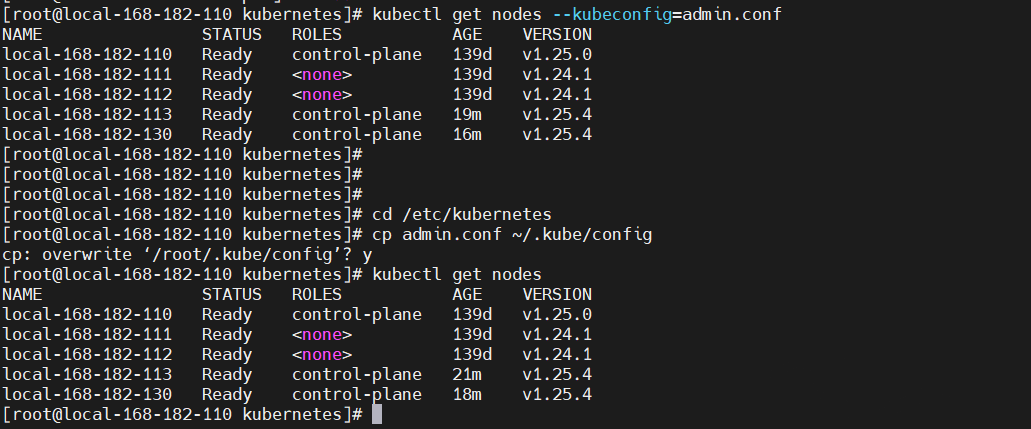
8)查看 ETCD
# 查看etcd pod
kubectl get pods -n kube-system |grep etcd
# 登录
POD_NAME=`kubectl get pods -n kube-system |grep etcd|head -1|awk '{print $1}'`
kubectl exec -it $POD_NAME -n kube-system -- sh
## 配置环境
alias etcdctl='etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key'
## 查看 etcd 集群成员列表
etcdctl member list9)解决 node 节点 NotReady 状态
1、从 master 节点拷贝 ca.crt 到 node 节点对应的目录
scp /etc/kubernetes/pki/ca.crt local-168-182-111:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/ca.crt local-168-182-112:/etc/kubernetes/pki/2、修改 node 节点的 kubelet.conf
把server: https://local-168-182-110:6443修改为现在 master 节点的地址server: https://cluster-endpoint:6443
sed -i 's/local-168-182-110/cluster-endpoint/g' /etc/kubernetes/kubelet.conf3、重启 docker 或者 containerd,kubelet
systemctl restart docker containerd kubelet四、故障模式测试
1)模拟 VIP 漂移
# 将master节点上的keepalived 停掉
systemctl stop keepalived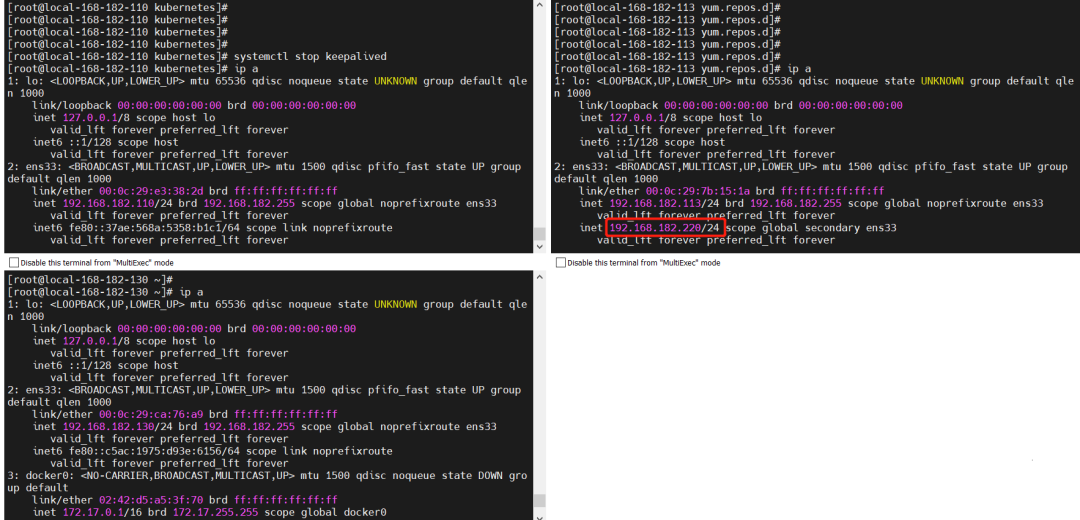
查看节点信息
kubectl get nodes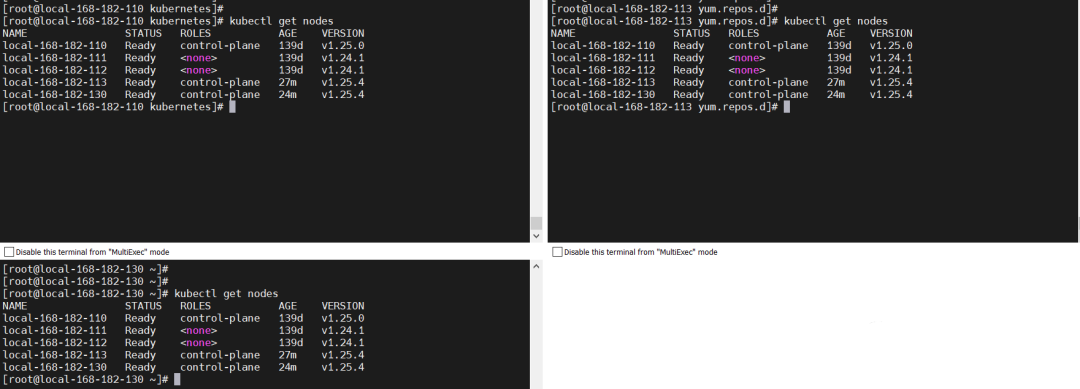
从上图可知 VIP 已经漂移到 master backup1 节点了,不影响集群,接下来恢复故障。
# 将master节点上的keepalived 启动
systemctl start keepalived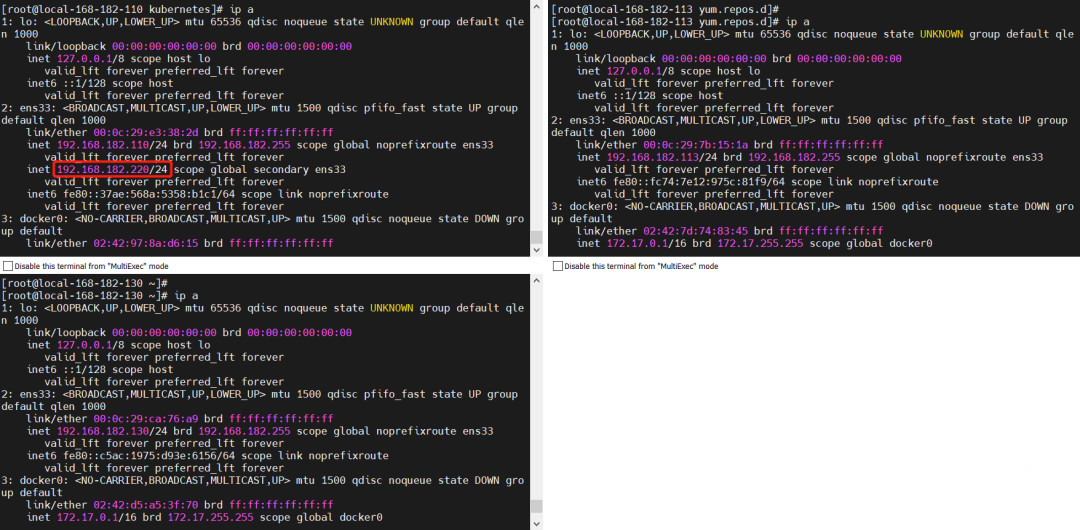
【结论】master 节点故障恢复后,VIP 会从新漂移回到原先的 master 节点。
查看节点信息
kubectl get nodes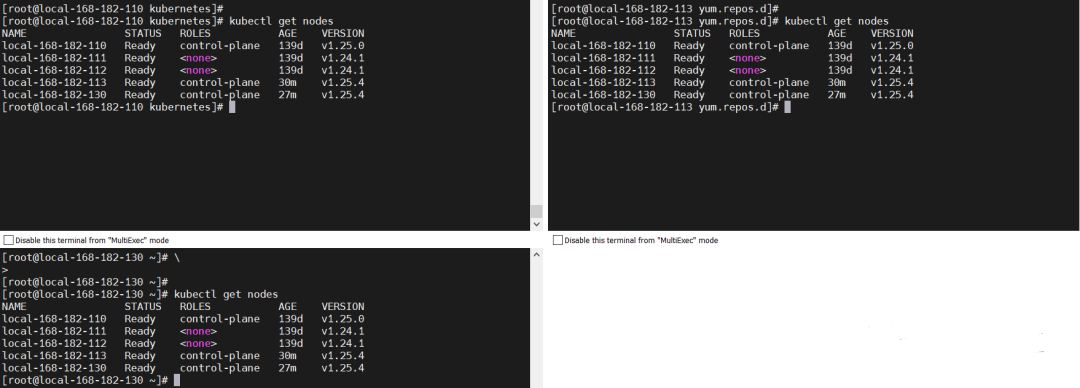
2)节点故障测试(一台 master 故障)
模拟 master 节点故障(手动关机)
# 关机192.168.182.110
showdown -h now
# 在192.168.182.113 backup master节点查看集群节点状态
kubectl get nodes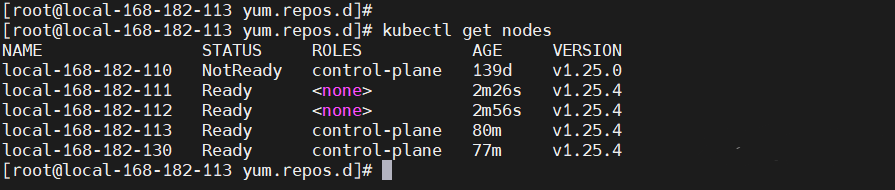
【结论】一台 master 故障,不影响集群。
3)master 节点故障模拟(两台 master 故障)
2、模拟 master 节点故障(手动关机)
# 关机192.168.182.113
showdown -h now
# 在192.168.182.130 backup master节点查看集群节点状态
kubectl get nodes【错误】
The connection to the server cluster-endpoint:6443 was refused - did you specify the right host or port?
发现两个 master 节点时,挂了一个 master 节点是不可用的。
原因:只要 Etcd 集群工作,KubernetesAPI 就能工作。当存在仲裁时,3 个 Etcd Pod 中至少有 2 个是活的,Etcd 集群就可以工作。如果 3 个 Etcd pod 中只有 1 个是活的,那么当不能调度新的 pod 并且不允许创建/更新/删除资源时,集群将进入只读状态。如果您的一些应用程序依赖于对 Kubernetes 对象的更新(比如一些 Kubernetes Operator) ,那么它们可能根本就不能正常工作。
小伙伴也可以去查看一下日志。stackoverflow 答案:https://stackoverflow.com/questions/55940128/what-happens-to-a-kubernetes-cluster-when-2-of-the-three-masters-in-a-replica-se/55940421#55940421
crictl ps 2>/dev/null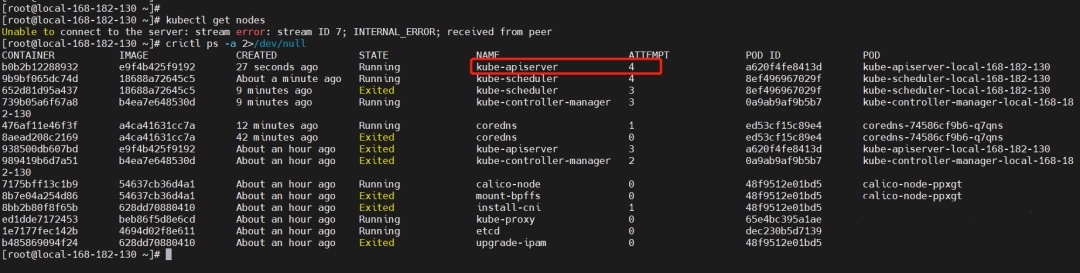
【建议】所以我们部署多 master 高可用节点数量必须大于等于 3,这样才能保证挂一个 master 节点,集群不会受影响。
K8S master 节点更换 IP 以及 master 高可用故障模拟测试就先到这里,有任何疑问欢迎给我留言,后续会持续更新










