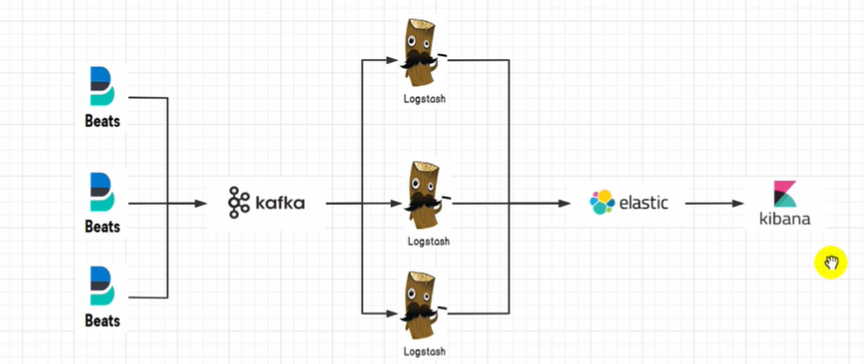
企业级架构ELKF集群、日志收集方案
「ELK安装文件」https://www.aliyundrive.com/s/zvTBLm7pSXd 提取码: j60q
kafka登入阿里云网盘下载,格式无法分享。或者下载地址:http://kafka.apache.org/downloads
ABC修改计算机名称
A服务器:hostnamectl set-hostname node1
B服务器:hostnamectl set-hostname node2
C服务器:hostnamectl set-hostname node3
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum install lrzsz vim java-1.8.0-openjdk java-1.8.0-openjdk-devel-y java –version -y
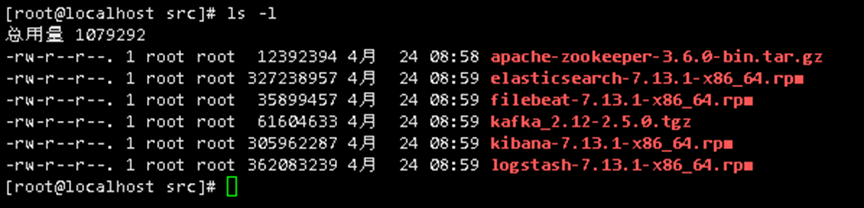
cd /usr/local/src/
apache-zookeeper-3.6.0-bin.tar.gz
elasticsearch-7.13.1-x86_64.rpm
filebeat-7.13.1-x86_64.rpm
kafka_2.12-2.5.0.tgz
kibana-7.13.1-x86_64.rpm
logstash-7.13.1-x86_64.rpm
ABC都要进行更新源,和安装javacurl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum install lrzsz vim java-1.8.0-openjdk java-1.8.0-openjdk-devel-y java –version -y
ABC安装ES集群服务,进行连接cd /usr/local/src/
yum localinstall elasticsearch-7.13.1-x86_64.rpm -y
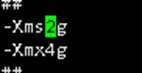
JVM的内存限制更改,根据实际环境调整,更具服务器内存修改,如果服务器8G,这里可以改为6G,给服务器预留1-2G即可vi /etc/elasticsearch/jvm.options
-Xms4g 改为 -Xmx2g
ES集群实战注意
集群交互是使用证书交互
搭建集群前需要先创建证书文件
ES集群交互CA证书创建 A服务器上/usr/share/elasticsearch/bin/elasticsearch-certutil ca #一直回车
查看证书位置ll -rht /usr/share/elasticsearch/elastic-stack-ca.p12
创建证书/usr/share/elasticsearch/bin/elasticsearch-certutil cert --ca /usr/share/elasticsearch/elastic-stack-ca.p12 #一直回车
查看证书ll -rht /usr/share/elasticsearch/elastic-certificates.p12
cp /usr/share/elasticsearch/elastic-certificates.p12 /etc/elasticsearch/elastic-certificates.p12
证书要求权限修改,不然集群搭建失败chmod 600 /etc/elasticsearch/elastic-certificates.p12
chown elasticsearch:elasticsearch /etc/elasticsearch/elastic-certificates.p12
吧加密ca证书拷贝到BC服务器scp /etc/elasticsearch/elastic-certificates.p12 10.10.1.4:/etc/elasticsearch/
scp /etc/elasticsearch/elastic-certificates.p12 10.10.1.5:/etc/elasticsearch/

md5sum /etc/elasticsearch/elastic-certificates.p12

B服务器和C服务器都要执行chmod 600 /etc/elasticsearch/elastic-certificates.p12
chown elasticsearch:elasticsearch /etc/elasticsearch/elastic-certificates.p12
ADC服务器都要进行修改vi /etc/elasticsearch/elasticsearch.yml
cluster.name: maixiaolun
node.name: node1 #服务器A就改为nede1,服务器B改为node2,服务器C改为node3
node.master: true
node.data: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.10.1.3", "10.10.1.4", "10.10.1.5"]
cluster.initial_master_nodes: ["10.10.1.3", "10.10.1.4", "10.10.1.5"]
xpack.security.enabled: true
xpack.monitoring.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /etc/elasticsearch/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /etc/elasticsearch/elastic-certificates.p12
ABC防火墙要放通端口firewall-cmd --zone=public --add-port=9300/tcp --permanent
firewall-cmd --zone=public --add-port=9300/udp --permanent
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --zone=public --add-port=9200/udp --permanent
firewall-cmd --zone=public --add-port=5601/tcp --permanent
firewall-cmd --zone=public --add-port=5601/udp --permanent
firewall-cmd --zone=public --add-port=80/tcp --permanent
firewall-cmd --zone=public --add-port=3000/tcp --permanent
重新载入
firewall-cmd --reload



systemctl enable elasticsearch
systemctl restart elasticsearch

出现valid,表示成功了
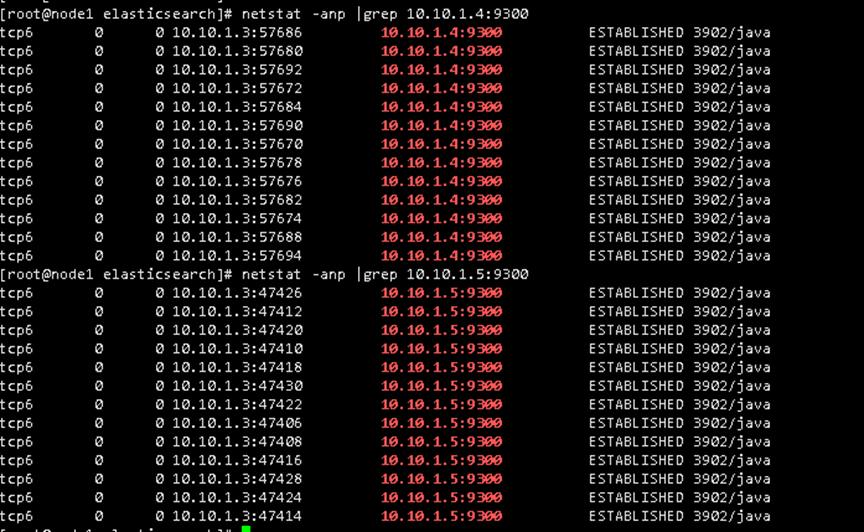
接下来是查看3台集群中间的互动yum -y install net-tools 安装 netstat
netstat -anp |grep 10.0.0.20:9300 查看集群之间的交互
检查9300端口连接情况
确认集群中所有es的日志正常再设置密码maixiaolun..123
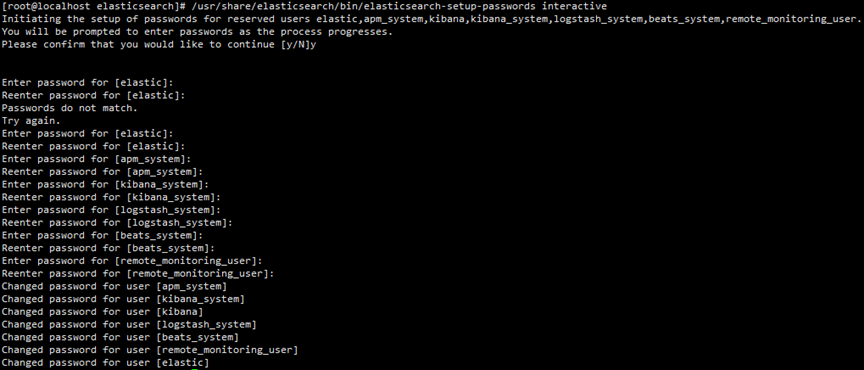
在主服务器(服务器A,想把那个当主服务器就在那个服务器上运行)上运行
ES设置密码/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
ES设置随机密码/usr/share/elasticsearch/bin/elasticsearch-setup-passwords auto
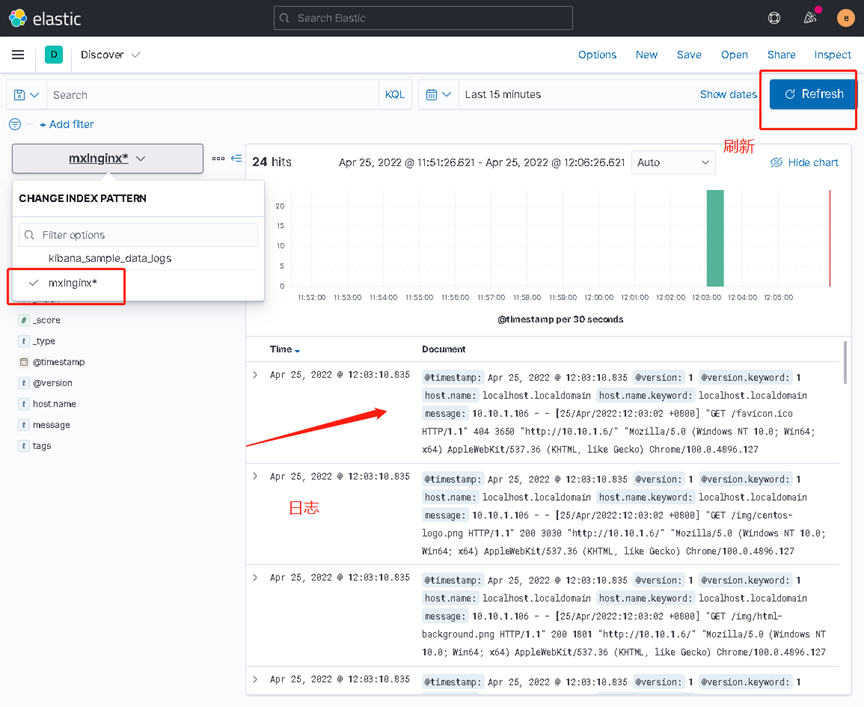
验证集群是否成功,标记为*的为master节点。网页访问或者curl访问
http://10.10.1.3:9200 账号:elastic 密码:刚刚设置的
http://10.10.1.3:9200/_cat/nodes?v //查看节点信息 带*的就是主的

http://xxx:9200/_cat/indices?v
curl -u elastic:maixiaolun..123 http://10.10.1.3:9200/_cat/nodes?v

B服务器安装Kibana (因为是前端,蹦了就蹦了,不要紧,所有不需要每个地方都搭建来)
cd /usr/local/src/
yum localinstall kibana-7.13.1-x86_64.rpm -y
Kibana配置连接ES集群vi /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://10.10.1.3:9200", "http://10.10.1.4:9200", "http://10.10.1.5:9200"]
elasticsearch.username: "elastic"
elasticsearch.password: "maixiaolun..123"
logging.dest: /tmp/kibana.log
B服务器Kibana的启动和访问systemctl enable kibana
systemctl restart kibana
Kibana监控开启netstat -tulnp
http://10.10.1.3:5601
账号:elastic
密码:maixiaolun..123
BC服务器安装logstash日志分析 (就是蹦了一台也不要紧,此做法为高可用做法,安装一台的话也是可以的)cd /usr/local/src/
yum localinstall logstash-7.13.1-x86_64.rpm -y
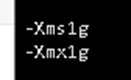
vi /etc/logstash/jvm.options
配置logstash配置文件vi /etc/logstash/conf.d/logstash.conf
#监听5044传来的日志
input { beats {
host => '0.0.0.0'
port => 5044
}
}
#这里是正则表达式,分析日志
filter {
grok {
match => {
"message" => '%{IP:remote_addr} - (%{WORD:remote_user}|-) [%
{HTTPDATE:time_local}] "%{WORD:method} %{NOTSPACE:request} HTTP/%
{NUMBER}" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS} %
{QS:http_user_agent}'
}
remove_field => ["message"]
}
date {
match => ["time_local", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
#发送给所有ES服务器
output {
elasticsearch {
hosts => ["http://10.10.1.3:9200", "http://10.10.1.4:9200", "http://10.10.1.5:9200"]
user => "elastic"
password => "maixiaolun..123"
index => "mxlnginx-%{+YYYY.MM.dd}"
}
}
#启动Logstash,配置重载: kill -1 pid
systemctl restart logstash
systemctl enable logstash
#等待启动,查看日志
/var/log/logstash 日志生成的地方
tail -f logstash-plain.log
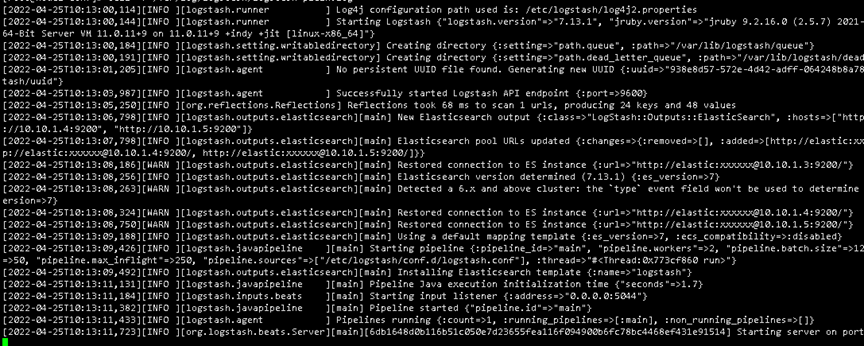
ZK集群部署
所有服务器都要进行安装cd /usr/local/src/
tar -zxvf apache-zookeeper-3.6.0-bin.tar.gz
mv apache-zookeeper-3.6.0-bin /usr/local/zookeeper
mkdir -pv /usr/local/zookeeper/data
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
zk集群至少需要三台机器
集群配置zoo.cfg
vi zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
clientPort=2181
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=10.10.1.3:2888:3888
server.2=10.10.1.4:2888:3888
server.3=10.10.1.5:2888:3888
更改zk集群的idvi /usr/local/zookeeper/data/myid
第一台就填写1
第二台就填写2
第三台就填写3


分别为1 2 3
systemctl管理vi /usr/lib/systemd/system/zookeeper.service
[Unit]
Description=zookeeper
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
User=root
[Install]
WantedBy=multi-user.target
启动zksystemctl enable zookeeper
systemctl restart zookeeper
启动zk集群查看状态cd /usr/local/zookeeper/bin/
./zkServer.sh start
./zkServer.sh status
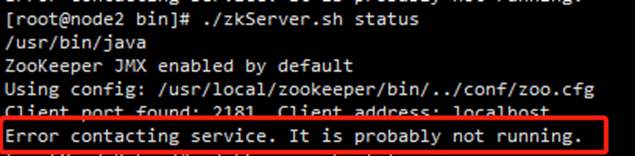
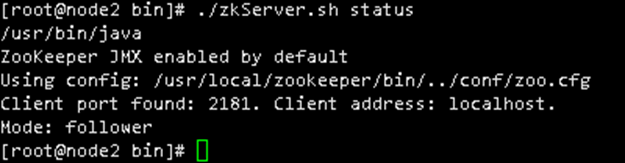
Kafka集群部署
下载地址:http://kafka.apache.org/downloads
安装cd /usr/local/src/
tar -zxvf kafka_2.12-2.5.0.tgz -C /usr/local/
Jvm内存修改/usr/local/kafka_2.12-2.5.0/bin/kafka-server-start.sh,根据实际情况修
改,每台服务器都要改

cd /usr/local/kafka_2.12-2.5.0/config/
vi server.properties

broker.id=0
listeners=PLAINTEXT://xxx:9092
log.retention.hours=1 #根据实际情况修改 日志保留时间
zookeeper.connect=xxx:2181,xxx:2181,xxx:2181
zookeeper.connection.timeout.ms=18000 改为 zookeeper.connection.timeout.ms=60000
拷贝到其他服务器上
scp server.properties 10.0.0.21:/usr/local/kafka_2.12-2.5.0/config/
然后在新的服务器上
vi /usr/local/kafka_2.12-2.5.0/config/server.properties
改listeners=PLAINTEXT://xxx:9092 对应当前服务器的ip
broker.id=0 改为broker.id=1
如果启动的时候报如下错误,是因为链接超时,吧60000改为 1200000也就是2分钟
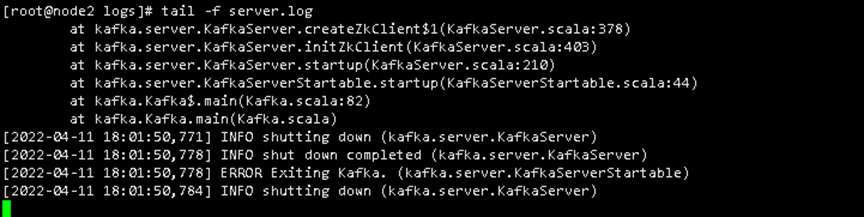
Kafka使用systemctl管理vi /usr/lib/systemd/system/kafka.service
[Unit]
Description=kafka
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/kafka_2.12-2.5.0/bin/kafka-server-start.sh /usr/local/kafka_2.12-2.5.0/config/server.properties
User=root
[Install]
WantedBy=multi-user.target
Kafka启动systemctl enable kafka
systemctl restart kafka
查看kafka日志cd /usr/local/kafka_2.12-2.5.0/logs
tail -f server.log
创建topic,创建成功说明kafka集群搭建成功--replication-factor 3 代表3台服务器
cd /usr/local/kafka_2.12-2.5.0/bin/
./kafka-topics.sh --create --zookeeper 10.10.1.4:2181 --replication-factor 3 --partitions 1 --topic maixiaolun #用这个测试
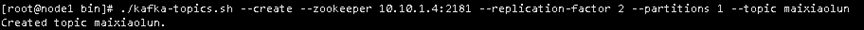
logstash获取kafka数据vi /etc/logstash/conf.d/logstash.conf
#获取kafka的日志
input {
kafka {
bootstrap_servers => "10.10.1.3:9092,10.10.1.4:9092,10.10.1.5:9092"
topics => ["mxlkafka"]
group_id => "mxlgroup"
codec => "json"
}
}
filter {
mutate {
remove_field => ["agent","ecs","log","input","[host][os]"]
}
}
#正则表达式分析日志
filter {
grok {
match => {
"message" => '%{IP:remote_addr} - (%{WORD:remote_user}|-) [%
{HTTPDATE:time_local}] "%{WORD:method} %{NOTSPACE:request} HTTP/%
{NUMBER}" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS} %
{QS:http_user_agent}'
}
remove_field => ["message"]
}
date {
match => ["time_local", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
}
#吧分析过后的日志发送给ES
output {
elasticsearch {
hosts => ["http://10.10.1.3:9200", "http://10.10.1.4:9200", "http://10.10.1.5:9200"]
user => "elastic"
password => "maixiaolun..123"
index => "mxlnginx-%{+YYYY.MM.dd}" #这里代表日志的名字,不通服务器可以写不通的名字
}
}
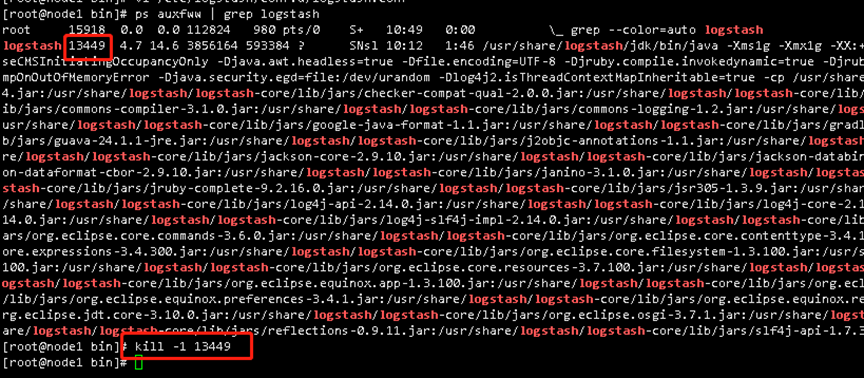
重载ps auxfww | grep logstash
kill -1 804
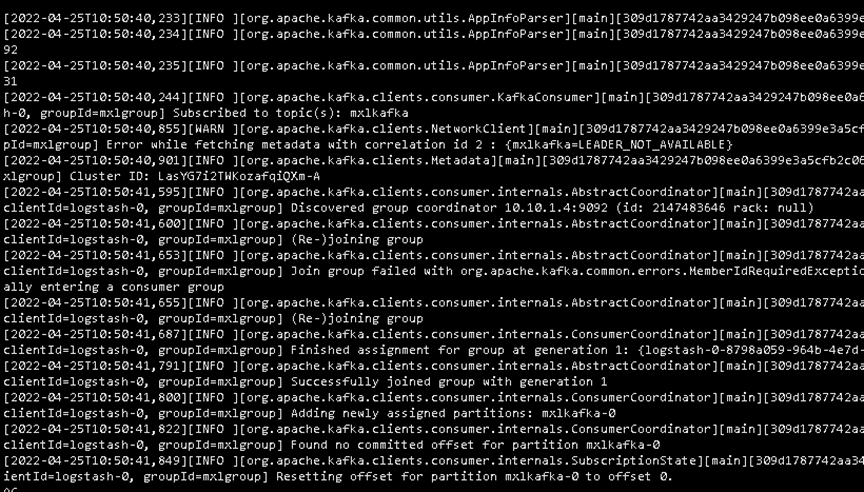
cd /usr/local/kafka_2.12-2.5.0/bin/
./kafka-consumer-groups.sh --bootstrap-server 10.10.1.4:9092 --list
./kafka-consumer-groups.sh --bootstrap-server 10.10.1.4:9092 --group mxlgroup -describe
LOG-END-OFFSET不断增大,LAG不堆积说明架构生效

LOG-END-OFFSET 一直增加就代表kafka在消费
LAG 一直在堆积
Logstash扩展
配置保持一致,启动即可
客户端D进行安装nginx进行测试数据是否传入服务器集群
安装nginx做测试,如果有其他服务可以直接测试yum install nginx -y
systemctl start nginx
安装filebeat,用于发送日志到服务器cd /usr/local/src/
yum localinstall filebeat-7.13.1-x86_64.rpm -y
配置filebeat进行监控nginx
vi /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
tail_files: true
backoff: "1s"
paths:
- /var/log/nginx/access.log
processors:
- drop_fields:
fields: ["agent","ecs","log","input"]
output:
kafka:
hosts: ["10.10.1.3:9092", "10.10.1.4:9092", "10.10.1.5:9092"]
topic: mxlkafka #这里代表日志的名字,不通服务器可以写不通的名字启动filebeatsystemctl start filebeat
systemctl enable filebeat
登入B服务器网页http://10.10.1.4:5601
账号:elastic
密码:maixiaolun..123
打开Stack Management
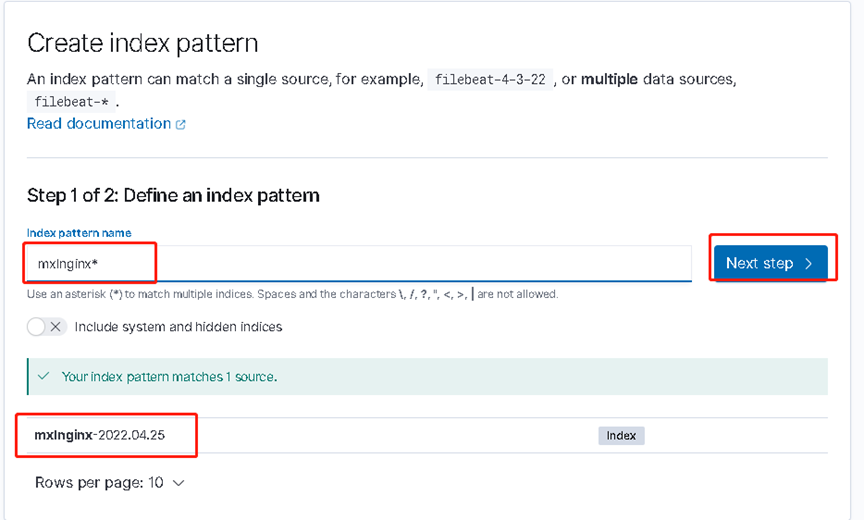
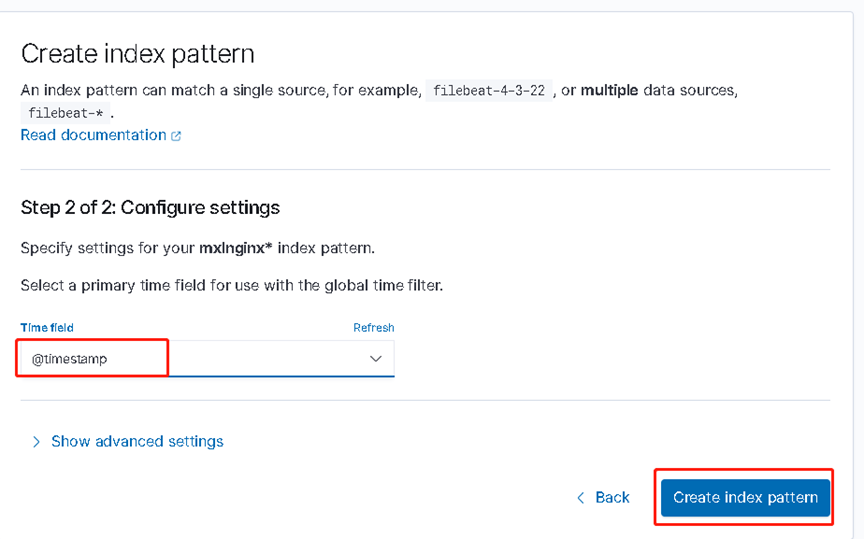
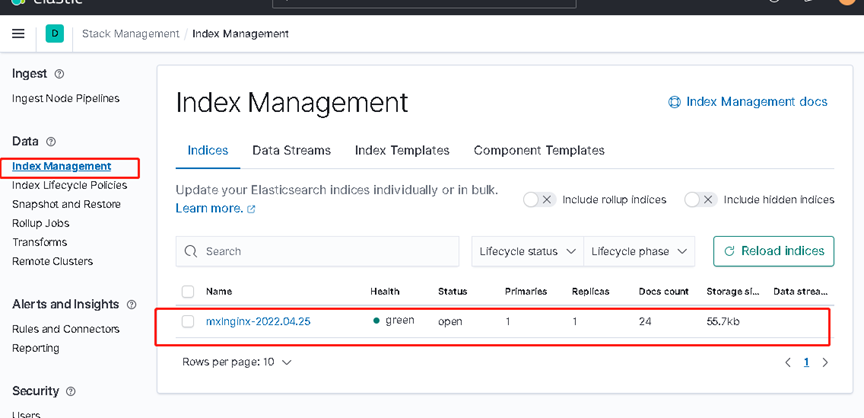
访问客户端地址nginx页面 10.10.1.6 多刷新几次