


K8S节点CPU升级,导致kubelet无法启动排障
事情背后的景象
k8s容量的时候时候时候,都都添加节点来问题。。这这几几几几天升级升级升级升级升级升级升级升级升级升级升级容量容量容量容量的时候时候碰到碰到个个了这个节点节点导致kubelet无法启动,然后大量pod被驱赶,报警电话响个不停。为了紧急救援,结果参与故障掩护。
现状获得
在知道,我后了了已经重启完毕的的的节点节点节点,开始节点,开始一系列的网络测试的日记,结果并非如此,一行日记让我看到了问题点:
E1121 23:43:52.644552 23453 policy_static.go:158] "Static policy invalid state, please drain node and remove policy state file" err="current set of available CPUs \"0-7\" doesn't match with CPUs in state \"0-3\""
E1121 23:43:52.644569 23453 cpu_manager.go:230] "Policy start error" err="current set of available CPUs \"0-7\" doesn't match with CPUs in state \"0-3\""
E1121 23:43:52.644587 23453 kubelet.go:1431] "Failed to start ContainerManager" err="start cpu manager error: current set of available CPUs \"0-7\" doesn't match with CPUs in state \"0-3\""说到这里,很多小伙伴会说:“就在这里??”。
真的的就这样。是因为啥呢?
kubelet启动因为有一个个:。表示--cpu-manager-policy表示在使用宿的是什么逻辑策略为这是一个绑定文件。
cpu_manager_state 内容大致长得如下:
{ "policyName": "static", "defaultCpuSet": "0-7", "checksum": 14413152 }k8s node节点cpu配置,cpu配置,静态cpu管理模式模式
原理分析
然而我们看到了整体现象和故障位置,不借用这个小问题我们一起启动温和下 k8s 的 cpu 管理规范。
官方文档如下:
https://kubernetes.io/zh-cn/docs/tasks/administer-cluster/cpu-management-policies/
当然我还想说很多不同的,关于CPU Manager整个架构,让小伙伴们有一个整体理解,能够更深入理解官方的cpu管理策略到底做什么。
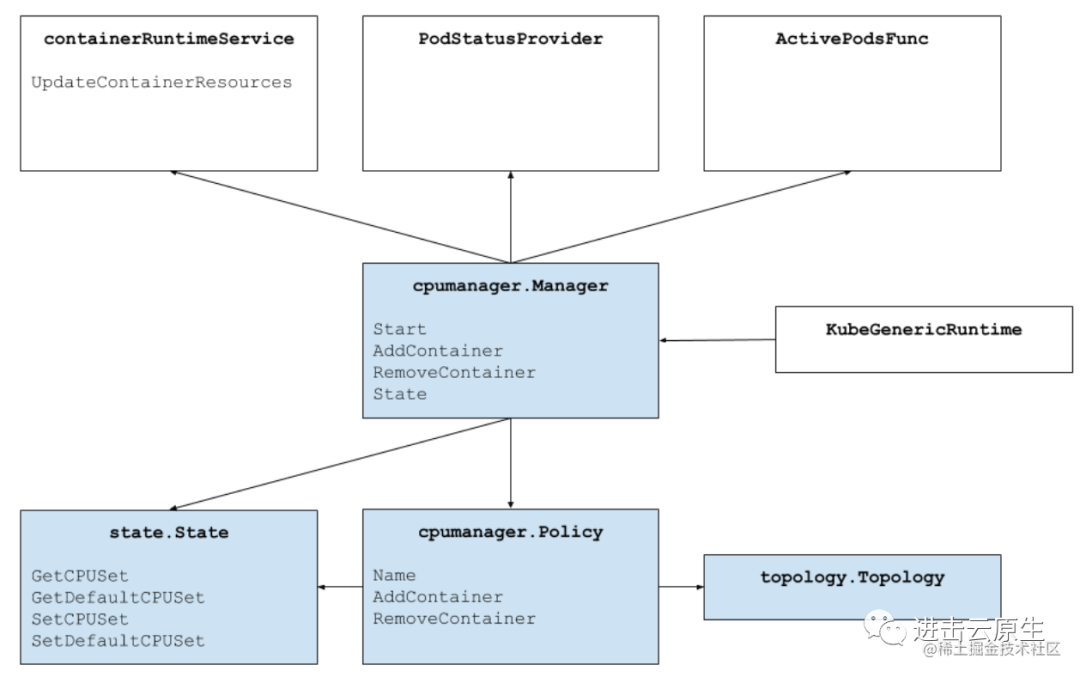
CPU 管理器架构
CPU Manager 为满脚条的容器分配指定的 CPUs 时,会尽数按 CPU Topology 来分配,也就是参考 CPU Affinity,按如下的优先顺序进入 CPUs 选择:(Logic CPUs 就是 Hyperthreads)
- 如果Container需要的Logic CPUs数量不少于单块CPU Socket中Logci CPUs数量,那么会优先把整块CPU Socket中的Logic CPUs分配给Container。
- 如果Container 减少余下请求的Logic CPU 数量不少于单块物理CPU Core 提供的Logic CPU 数量,那么会优先把整块物理CPU Core 上的Logic CPU 分配给Container。
Container 托余请求的Logic CPUs 那么从按以下规则排列好的Logic CPUs 列表中选:
- 同一个插槽上可用的CPU数量
- 同一颗心上可用的CPU数量
参考代码:pkg/kubelet/cm/cpumanager/cpu_assignment.go
func takeByTopology(topo *topology.CPUTopology, availableCPUs cpuset.CPUSet, numCPUs int) (cpuset.CPUSet, error) {
acc := newCPUAccumulator(topo, availableCPUs, numCPUs)
if acc.isSatisfied() {
return acc.result, nil
}
if acc.isFailed() {
return cpuset.NewCPUSet(), fmt.Errorf("not enough cpus available to satisfy request")
}
// Algorithm: topology-aware best-fit
// 1. Acquire whole sockets, if available and the container requires at
// least a socket's-worth of CPUs.
for _, s := range acc.freeSockets() {
if acc.needs(acc.topo.CPUsPerSocket()) {
glog.V(4).Infof("[cpumanager] takeByTopology: claiming socket [%d]", s)
acc.take(acc.details.CPUsInSocket(s))
if acc.isSatisfied() {
return acc.result, nil
}
}
}
// 2. Acquire whole cores, if available and the container requires at least
// a core's-worth of CPUs.
for _, c := range acc.freeCores() {
if acc.needs(acc.topo.CPUsPerCore()) {
glog.V(4).Infof("[cpumanager] takeByTopology: claiming core [%d]", c)
acc.take(acc.details.CPUsInCore(c))
if acc.isSatisfied() {
return acc.result, nil
}
}
}
// 3. Acquire single threads, preferring to fill partially-allocated cores
// on the same sockets as the whole cores we have already taken in this
// allocation.
for _, c := range acc.freeCPUs() {
glog.V(4).Infof("[cpumanager] takeByTopology: claiming CPU [%d]", c)
if acc.needs(1) {
acc.take(cpuset.NewCPUSet(c))
}
if acc.isSatisfied() {
return acc.result, nil
}
}
return cpuset.NewCPUSet(), fmt.Errorf("failed to allocate cpus")
}发现 CPU 拓扑
参考代码:vendor/github.com/google/cadvisor/info/v1/machine.go
type MachineInfo struct {
// The number of cores in this machine.
NumCores int `json:"num_cores"`
...
// Machine Topology
// Describes cpu/memory layout and hierarchy.
Topology []Node `json:"topology"`
...
}
type Node struct {
Id int `json:"node_id"`
// Per-node memory
Memory uint64 `json:"memory"`
Cores []Core `json:"cores"`
Caches []Cache `json:"caches"`
}cAdvisor 通过GetTopology 完成cpu 拓普信息生成,主要是读取主机上/proc/cpuinfo 中信息来冲洗CPU Topology,通过读取/sys/devices/system/cpu/cpu 来获得cpu cache 。
参考代码:vendor/github.com/google/cadvisor/info/v1/machine.go
func GetTopology(sysFs sysfs.SysFs, cpuinfo string) ([]info.Node, int, error) {
nodes := []info.Node{}
...
return nodes, numCores, nil
}创建 pod 过程
对于前面提到的静态策略情况下Container如何创建呢?kubelet会为其选择约定的cpu affinity来为其选择最佳的CPU Set。
Container的创建时CPU Manager工作流程大致下:
- Kuberuntime 调用容器运行时去创建容器。
- Kuberuntime 将容器传送给 CPU 管理器处理。
- CPU Manager 为 Container 按照静策略进行处理。
- CPU Manager 从当前 Shared Pool 中选择“最佳”Set 拓结构的 CPU,对于不满足 Static Policy 的 Contianer,则返回 Shared Pool 中所有 CPU 组合的 Set。
- CPU Manager 将指针对容器的 CPUs 分配情况记录到 Checkpoint State 中,并从 Shared Pool 中删除刚分配的 CPUs。
- CPU Manager 再从 state 中读取该 Container 的 CPU 分配信息,然后通过 UpdateContainerResources cRI 接口将其更新到 Cpuset Cgroups 中,例如对于非 Static Policy Container。
- Kuberuntime 调用容器运行时启动该容器。
参考代码:pkg/kubelet/cm/cpumanager/cpu_manager.go
func (m *manager) AddContainer(pod *v1.Pod, container *v1.Container, containerID string) {
m.Lock()
defer m.Unlock()
if cset, exists := m.state.GetCPUSet(string(pod.UID), container.Name); exists {
m.lastUpdateState.SetCPUSet(string(pod.UID), container.Name, cset)
}
m.containerMap.Add(string(pod.UID), container.Name, containerID)
}参考代码:pkg/kubelet/cm/cpumanager/policy_static.go
func NewStaticPolicy(topology *topology.CPUTopology, numReservedCPUs int, reservedCPUs cpuset.CPUSet, affinity topologymanager.Store, cpuPolicyOptions map[string]string) (Policy, error) {
opts, err := NewStaticPolicyOptions(cpuPolicyOptions)
if err != nil {
return nil, err
}
klog.InfoS("Static policy created with configuration", "options", opts)
policy := &staticPolicy{
topology: topology,
affinity: affinity,
cpusToReuse: make(map[string]cpuset.CPUSet),
options: opts,
}
allCPUs := topology.CPUDetails.CPUs()
var reserved cpuset.CPUSet
if reservedCPUs.Size() > 0 {
reserved = reservedCPUs
} else {
// takeByTopology allocates CPUs associated with low-numbered cores from
// allCPUs.
//
// For example: Given a system with 8 CPUs available and HT enabled,
// if numReservedCPUs=2, then reserved={0,4}
reserved, _ = policy.takeByTopology(allCPUs, numReservedCPUs)
}
if reserved.Size() != numReservedCPUs {
err := fmt.Errorf("[cpumanager] unable to reserve the required amount of CPUs (size of %s did not equal %d)", reserved, numReservedCPUs)
return nil, err
}
klog.InfoS("Reserved CPUs not available for exclusive assignment", "reservedSize", reserved.Size(), "reserved", reserved)
policy.reserved = reserved
return policy, nil
}
func (p *staticPolicy) Allocate(s state.State, pod *v1.Pod, container *v1.Container) error {
if numCPUs := p.guaranteedCPUs(pod, container); numCPUs != 0 {
klog.InfoS("Static policy: Allocate", "pod", klog.KObj(pod), "containerName", container.Name)
// container belongs in an exclusively allocated pool
if p.options.FullPhysicalCPUsOnly && ((numCPUs % p.topology.CPUsPerCore()) != 0) {
// Since CPU Manager has been enabled requesting strict SMT alignment, it means a guaranteed pod can only be admitted
// if the CPU requested is a multiple of the number of virtual cpus per physical cores.
// In case CPU request is not a multiple of the number of virtual cpus per physical cores the Pod will be put
// in Failed state, with SMTAlignmentError as reason. Since the allocation happens in terms of physical cores
// and the scheduler is responsible for ensuring that the workload goes to a node that has enough CPUs,
// the pod would be placed on a node where there are enough physical cores available to be allocated.
// Just like the behaviour in case of static policy, takeByTopology will try to first allocate CPUs from the same socket
// and only in case the request cannot be sattisfied on a single socket, CPU allocation is done for a workload to occupy all
// CPUs on a physical core. Allocation of individual threads would never have to occur.
return SMTAlignmentError{
RequestedCPUs: numCPUs,
CpusPerCore: p.topology.CPUsPerCore(),
}
}
if cpuset, ok := s.GetCPUSet(string(pod.UID), container.Name); ok {
p.updateCPUsToReuse(pod, container, cpuset)
klog.InfoS("Static policy: container already present in state, skipping", "pod", klog.KObj(pod), "containerName", container.Name)
return nil
}
// Call Topology Manager to get the aligned socket affinity across all hint providers.
hint := p.affinity.GetAffinity(string(pod.UID), container.Name)
klog.InfoS("Topology Affinity", "pod", klog.KObj(pod), "containerName", container.Name, "affinity", hint)
// Allocate CPUs according to the NUMA affinity contained in the hint.
cpuset, err := p.allocateCPUs(s, numCPUs, hint.NUMANodeAffinity, p.cpusToReuse[string(pod.UID)])
if err != nil {
klog.ErrorS(err, "Unable to allocate CPUs", "pod", klog.KObj(pod), "containerName", container.Name, "numCPUs", numCPUs)
return err
}
s.SetCPUSet(string(pod.UID), container.Name, cpuset)
p.updateCPUsToReuse(pod, container, cpuset)
}
// container belongs in the shared pool (nothing to do; use default cpuset)
return nil
}
func (p *staticPolicy) allocateCPUs(s state.State, numCPUs int, numaAffinity bitmask.BitMask, reusableCPUs cpuset.CPUSet) (cpuset.CPUSet, error) {
klog.InfoS("AllocateCPUs", "numCPUs", numCPUs, "socket", numaAffinity)
allocatableCPUs := p.GetAllocatableCPUs(s).Union(reusableCPUs)
// If there are aligned CPUs in numaAffinity, attempt to take those first.
result := cpuset.NewCPUSet()
if numaAffinity != nil {
alignedCPUs := cpuset.NewCPUSet()
for _, numaNodeID := range numaAffinity.GetBits() {
alignedCPUs = alignedCPUs.Union(allocatableCPUs.Intersection(p.topology.CPUDetails.CPUsInNUMANodes(numaNodeID)))
}
numAlignedToAlloc := alignedCPUs.Size()
if numCPUs < numAlignedToAlloc {
numAlignedToAlloc = numCPUs
}
alignedCPUs, err := p.takeByTopology(alignedCPUs, numAlignedToAlloc)
if err != nil {
return cpuset.NewCPUSet(), err
}
result = result.Union(alignedCPUs)
}
// Get any remaining CPUs from what's leftover after attempting to grab aligned ones.
remainingCPUs, err := p.takeByTopology(allocatableCPUs.Difference(result), numCPUs-result.Size())
if err != nil {
return cpuset.NewCPUSet(), err
}
result = result.Union(remainingCPUs)
// Remove allocated CPUs from the shared CPUSet.
s.SetDefaultCPUSet(s.GetDefaultCPUSet().Difference(result))
klog.InfoS("AllocateCPUs", "result", result)
return result, nil
}删除 pod 过程
当这些通过 CPU Managers 分配 CPUs 的 Container 要删除时,CPU Manager 工作流大致如下:
- Kuberuntime 会调用 CPU Manager 去按静态策略中定义分配处理。
- CPU Manager 将容器分配的 Cpu Set 重新归还到 Shared Pool 中。
- Kuberuntime 调用容器运行时移去该容器。
- CPU Manager 会异步进行协调循环,为使用共享池中的 Cpus 容器更新 CPU 集合。
参考代码:pkg/kubelet/cm/cpumanager/cpu_manager.go
func (m *manager) RemoveContainer(containerID string) error {
m.Lock()
defer m.Unlock()
err := m.policyRemoveContainerByID(containerID)
if err != nil {
klog.ErrorS(err, "RemoveContainer error")
return err
}
return nil
}参考代码:pkg/kubelet/cm/cpumanager/policy_static.go
func (p *staticPolicy) RemoveContainer(s state.State, podUID string, containerName string) error {
klog.InfoS("Static policy: RemoveContainer", "podUID", podUID, "containerName", containerName)
if toRelease, ok := s.GetCPUSet(podUID, containerName); ok {
s.Delete(podUID, containerName)
// Mutate the shared pool, adding released cpus.
s.SetDefaultCPUSet(s.GetDefaultCPUSet().Union(toRelease))
}
return nil
}处理方法
知道了异常的原因和以及具体原因,解决办法也非常好弄就两步:
- 删除原来有 cpu_manager_state 文件
- 重启 kubelet










