


Kubernetes-宿主监控实操
生产环境大都是在 Linux 下的,所以这篇文章我们先来分享如何使用 Categraf 采集 Linux OS 相关的指标。读完本篇内容,你应该可以完成机器层面的监控了。
咱们这个系列是讲解 Kubernetes 监控,Kubernetes 自身也是要跑在机器上的,那机器的监控自然也是整个体系的一环。机器层面的监控分为两部分,带内网络和带外网络,通过带内网络做监控主要是在OS里部署 agent 的方式,获取 OS 的 CPU、内存、磁盘、IO、网络、进程等相关监控指标。带外监控,主要是走带外管理卡,通过 IPMI、SNMP 协议,获取硬件健康状况。
原理概述
Categraf 作为一款 agent 需要部署到所有目标机器上,因为采集 CPU、内存、IO、进程等指标,是需要读取 OS 里的一些信息的,远程读取不了。采集到数据之后,做格式转换,传输给监控服务端,这里我们使用 Nightingale 作为监控服务端软件。
Categraf 推送监控数据到服务端,走的是 Prometheus 的 RemoteWrite 协议,是基于 protobuf 的 HTTP 协议,所以,不止是 Nightingale,所有支持 RemoteWrite 的后端,都可以和 Categraf 对接。
软件下载
Categraf 的 GitHub 地址是:https://github.com/flashcatcloud/categraf,从 releases 下可以找到已经提前编译好的二进制,我的环境是 CentOS7,所以,选择 linux-amd64 的 tarball。
软件配置
Categraf 下载之后解压缩,最需要注意的配置是监控数据的推送地址,即下面的部分:
[[writers]]
url = "http://127.0.0.1:19000/prometheus/v1/write"
默认给的这个地址,是 n9e-server 的 RemoteWrite 数据接收地址,如果你也是用的 Nightingale,把 127.0.0.1:9090 改成你的 n9e-server 的地址即可,url 路径不用变。
如果你想让 Categraf 把数据推给 Prometheus,也 OK,此时不但要修改 IP:端口 为你的环境的 Prometheus 的地址,还要修改 url 路径,因为 Prometheus 的 RemoteWrite 数据接收地址是 /api/v1/write。最后,还要注意,Prometheus 进程启动的时候,需要增加一个启动参数:--enable-feature=remote-write-receiver,重启 Prometheus 即可接收 RemoteWrite 数据。
另外就是插件的配置,Categraf 是插件架构,内置很多采集插件,采集CPU的数据使用cpu插件,采集内存的数据使用mem插件,Categraf 的 conf 目录下,可以看到很多 input. 相关的目录,就是一个个插件的配置目录。如果有些插件不需要,删除对应的 input. 目录即可。
启动 Categraf
启动之前先做个测试,通过 ./categraf --test 看看有没有报错,正常情况的话会在命令行输出采集到的监控数据。下面是我的环境下的运行结果,供参考:
[root@tt-fc-dev01.nj categraf]# ./categraf --test --inputs mem:system
2022/11/05 09:14:31 main.go:110: I! runner.binarydir: /home/work/go/src/categraf
2022/11/05 09:14:31 main.go:111: I! runner.hostname: tt-fc-dev01.nj
2022/11/05 09:14:31 main.go:112: I! runner.fd_limits: (soft=655360, hard=655360)
2022/11/05 09:14:31 main.go:113: I! runner.vm_limits: (soft=unlimited, hard=unlimited)
2022/11/05 09:14:31 config.go:33: I! tracing disabled
2022/11/05 09:14:31 provider.go:63: I! use input provider: [local]
2022/11/05 09:14:31 agent.go:85: I! agent starting
2022/11/05 09:14:31 metrics_agent.go:93: I! input: local.mem started
2022/11/05 09:14:31 metrics_agent.go:93: I! input: local.system started
2022/11/05 09:14:31 prometheus_scrape.go:14: I! prometheus scraping disabled!
2022/11/05 09:14:31 agent.go:96: I! agent started
09:14:31 system_load_norm_5 agent_hostname=tt-fc-dev01.nj 0.3
09:14:31 system_load_norm_15 agent_hostname=tt-fc-dev01.nj 0.2675
09:14:31 system_uptime agent_hostname=tt-fc-dev01.nj 7307063
09:14:31 system_load1 agent_hostname=tt-fc-dev01.nj 1.66
09:14:31 system_load5 agent_hostname=tt-fc-dev01.nj 1.2
09:14:31 system_load15 agent_hostname=tt-fc-dev01.nj 1.07
09:14:31 system_n_cpus agent_hostname=tt-fc-dev01.nj 4
09:14:31 system_load_norm_1 agent_hostname=tt-fc-dev01.nj 0.415
09:14:31 mem_swap_free agent_hostname=tt-fc-dev01.nj 0
09:14:31 mem_used agent_hostname=tt-fc-dev01.nj 5248593920
09:14:31 mem_high_total agent_hostname=tt-fc-dev01.nj 0
09:14:31 mem_huge_pages_total agent_hostname=tt-fc-dev01.nj 0
09:14:31 mem_low_free agent_hostname=tt-fc-dev01.nj 0
...
Linux 下启动 Categraf 显然推荐使用 systemd 来启动,service 样例文件已经给大家准备好了,在 conf/categraf.service。
导入配置
Categraf 除了要做 All-in-one 的采集器,还希望沉淀最佳实践出来,比如 MySQL的监控采集插件 的代码目录里,大家可以看到有 alerts.json 表示告警规则,导入夜莺即可使用,还有 dashboard-x.json 表示监控大盘,也是导入夜莺即可使用。dashboard-x.json 可能有多个,是因为可能有不同的查看维度,你可以都导入看看,相中哪个就用哪个。
机器相关的指标,分成了很多个插件,比如 cpu、mem、disk、net 等等,但是这些数据一般会放到一张大盘里查看,所以机器相关的告警规则和监控大盘的json放到了system目录。导入夜莺之后的查看效果如下:
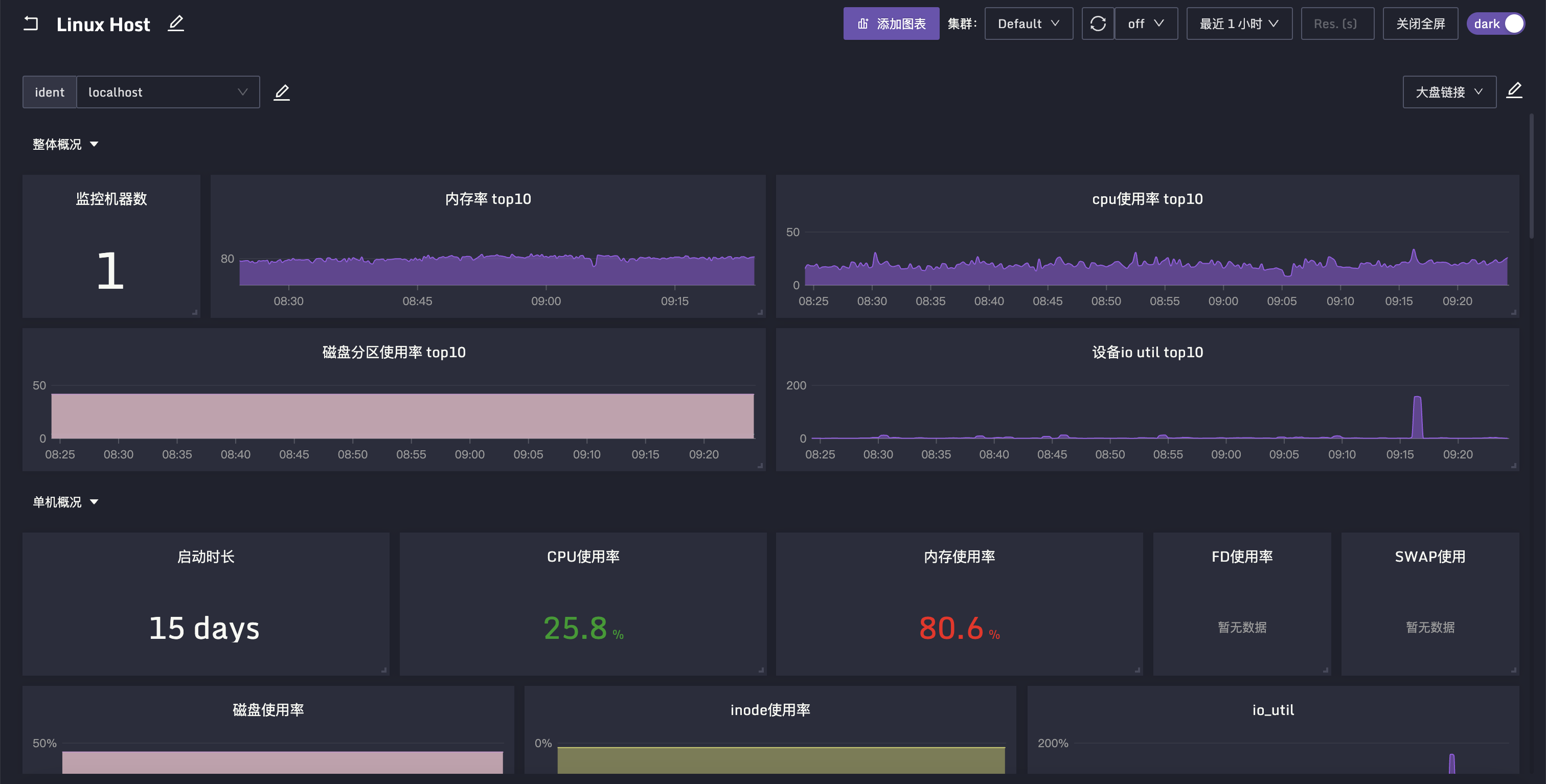
另外说一下,Categraf 虽然希望沉淀出最佳实践,但是采集插件实在是太多了,而且还在逐步引入更多采集插件,有些插件我们自己也没有测试环境,需要依靠社区的力量,大家一起维护这些监控大盘和告警规则,如果有的插件缺失,欢迎你来提交PR补充,为社区建设添砖加瓦,利人利己。
总结
Kubernetes 宿主的监控,和之前传统的物理机虚拟机时代的机器监控没有本质区别。下一节开始,我们将为大家介绍如何监控工作负载节点,包括 Pod 容器、Kubelet、Kube-Proxy 等组件。










